
Merhaba, bu yazıda Titanik'in yolcularının bilgilerini kullanarak bir karar ağacı modeli oluşturup onu görselleştireceğiz. Bu yazının "notebook" olarak İngilizce haline şuradan ulaşabilirsiniz.
Veriyi İşlemek
İlk olarak bize verilen veriler üzerinde işlem yapılabilir hale gelmeliyiz. Bunun için ise veriler üzerinde oynayabilmemizi sağlayan iki kütüphaneyi tanıtarak başlıyoruz.
- Numpy: Veriler üzerinde matris tabanlı işlemler yapabilmemizi sağlıyor.
- Pandas: Kullanılması kolay veri yapıları ve verilerle işlemler yapmamızı sağlayan bir kütüphane.
Ardından da veri üzerinde oynayabilmek için pandas kütüphanesinin data frame tipini kullanarak internet üzerinden yolcuların bilgilerini alıyorum. Eğer böyle çalıştırmak istemezseniz yazının girişinde paylaşmış olduğum kaggle linkinden data setini indirip makinenizdeki adresi vererek çalıştırabilirsiniz.
import numpy as np
import pandas as pd
# Verilere internet üzerinden erişiyorum.
df = pd.read_csv("https://storage.googleapis.com/kaggle-competitions-data/kaggle/3136/train.csv?GoogleAccessId=web-data@kaggle-161607.iam.gserviceaccount.com&Expires=1545841584&Signature=hMUrGWx0cz6kvPVVfHob%2FrD5DarBMJ8gZuej3Okok5oc%2BvW1d2iI1PkaBJtnjDFzazC4Iy1lyVl1W7MbRPNSO9gjgIny3a7oBKdEMDCpAxVWUxc7LGLPGGyEHqBFWKaQ9oXMXsi1AK%2FTVjTpMPJl2qLYJfmTGTd1co%2BRRnJOV1QHC23qqtqQkposVKLNzVYeBJ81nTLewOWG7Y5koTQ3YwYuh5YatnnZkdse4j1OJIdA3q8D%2B6%2F2RRGX71zIksqU5fnfmu8s5v2QLgqfX7byDoSdoOSHzvmekIdCeMDYQNLzYtwGQXNT5mVl21umU%2FW7UCNaFcoZr2XpkuCVByKNUw%3D%3D")
# Elimdeki veri setinden düşürülecek olan sütün isimlerini belirliyorum ve ardından düşürüyorum.
dropList = ["Ticket", "Name", "Cabin", "Embarked", "Age", "PassengerId"]
df.drop(dropList, axis=1, inplace=True)
df.info()
Çıktısı:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 6 columns):
Survived 891 non-null int64
Pclass 891 non-null int64
Sex 891 non-null object
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null float64
dtypes: float64(1), int64(4), object(1)
memory usage: 41.8+ KB
Elimdeki verilerle bir işlem yapabilmem için hepsi aynı veri tipinde olmalı. Bu yüzden yukardaki çıktıdan sizin de saptayabileceğiniz üzere "int64" olmayan değişkenleri kullanabilmek için aşağıdaki işlemleri yaparak yukardaki gibi bilgileri bir kez daha çıktı alıyorum ki rahat kıyaslayabilin.
df['Sex'] = pd.DataFrame(np.where(df['Sex'] == 'male', 1, 0))
df["Fare"] = df["Fare"].fillna(0.0).apply(np.int64)
df.info()
Çıktısı:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 6 columns):
Survived 891 non-null int64
Pclass 891 non-null int64
Sex 891 non-null int64
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null int64
dtypes: int64(6)
memory usage: 41.8 KB
Göreceğiniz üzere herhangi bir boş veri içermeyen ve hepsi aynı veri tipinde olan veri setim hazır. Veri setim ile işlem yapabilmem için tahmin etmeye çalıştığım veriyi ayırarak yeni bir data frame oluşturuyorum.
X = df.drop(["Survived"], axis=1)
y = df.Survivedpy
Makine Öğrenmesi Kısmı
İlk kısımdaki kütüphaneleri modeli eğitmek için, ikinci kısımdaki kütüphaneleri de oluşturmuş olduğum modeli görselleştirmek için kullanıyorum. Tanıtmış olduğum kütüphanelerden de fark edebileceğiniz üzere "Decision Tree" modelini kullandım. Eğer belli bir projede en iyi skoru almak için uğraşıyorsanız, diğer modellerde de test yapıp en yüksek performansı sağlayan modeli tercih etmelisiniz. Fakat şu an benim karar ağacı modelini kullanma sebebim ise görselleştirmesinin çok kolay olması. Bunu tercih eden müşterileriniz olabilir. "Black Box" olan modelleri açıklamada sorun yaşayacaklarından kolay okunabilir bir şey olmasını talep edebilirler. Bu yüzden bende bu tarz bir senaryoya uygun olarak Karar Ağacı modelini tercih ettim.
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix as cm
import matplotlib.pyplot as plt
# Çıktılar için
from sklearn.tree import export_graphviz
from sklearn import tree
from IPython.display import SVG
from graphviz import Source
from IPython.display import display
Yukarıda oluşturmuş olduğum "X" ve "y" verilerini kullanarak bir karar ağacı modeli oluşturdum.
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
d_tree1 = DecisionTreeClassifier(max_depth=2, random_state=42)
d_tree1.fit(X_train, y_train)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=42,
splitter='best')
Kurmuş olduğum model ile, yukarıda ayırmış olduğum "test" verilerinin skoruna bakıyorum. Çıktıları ise confusion matrix olarak çıktı alıyorum. Daha önce hiç kullanmadıysanız eğer confusion matrixlerin okuması şöyle yapılır:
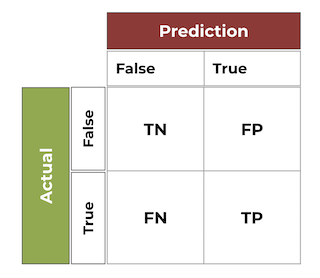
TN: True Negative
FP: False Positive
FN: False Negative
TP: True Positive
Altında ise kurtulan insanaların yüzde kaçını doğru tahmin edebilmişiz (Bu örnekte %77,2 çıkmış) bunu görüyoruz.
predictions = d_tree1.predict(X_test)
score = round(accuracy_score(y_test, predictions), 3)
cm1 = cm(y_test, predictions)
print("Confisuon Matrix:\n", cm1)
print("Our model score:", score)
Çıktısı:
Confisuon Matrix:
[[152 5]
[ 56 55]]
Our model score: 0.772
Girişte anlattığım görselleştirme kısmı ise burada. Makinemizin oluşturduğu modeli bir karar ağacı olarak görebiliyoruz. Elde ettiğimiz bu karar ağacına göre: eğer yolcu erkek ise parasına, kadın ise sınıfına bakarak karar veriyor. Buradaki kararların hepsinin makine tabanlı olduğunu unutmamak gerekir.
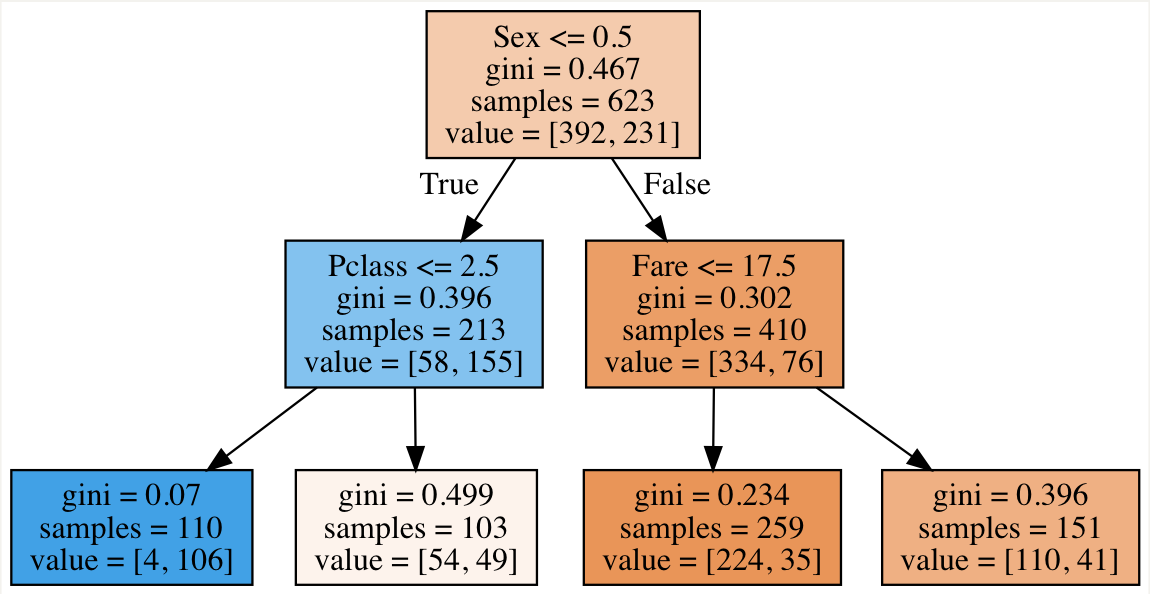
Şimdi çıkartacağımız grafikte ise bir yolcunun kurtulup/kurtulmadığına bakarken en etkili olan değişkenleri görüyoruz.
from sklearn import ensemble
plt.figure(figsize=(16, 9))
d_tree2 = DecisionTreeClassifier(max_depth=8, random_state=42)
d_tree2.fit(X_train, y_train)
ranking = d_tree2.feature_importances_
features = np.argsort(ranking)[::-1][:10]
columns = X.columns
plt.bar(range(len(features)), ranking[features], align="center")
plt.xticks(range(len(features)), columns[features])
plt.show()
Çıktısı:
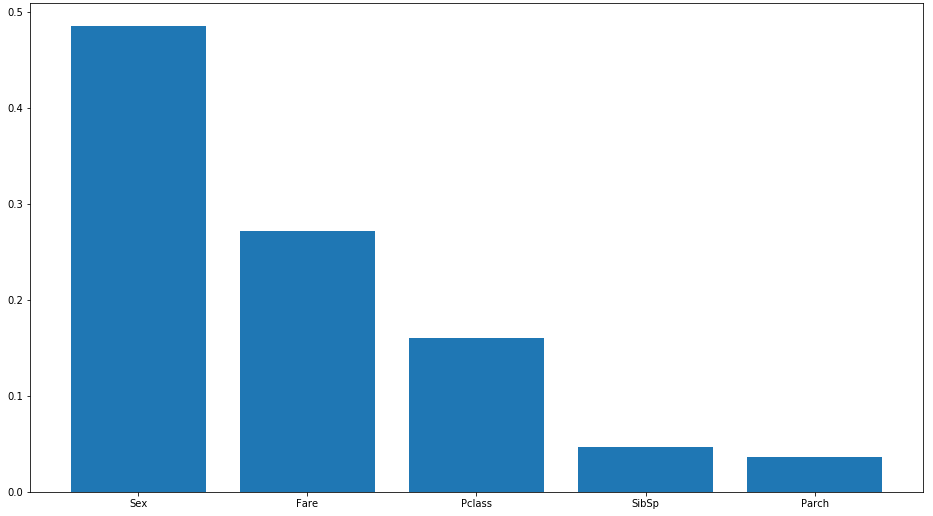
Kişinin hayatta kalması için en önemli değişkenin cinsiyetini olduğunu görebiliyoruz.
Yazımı okuduğunuz için teşekkür ederim. Bir hatamı görürseniz, paylaşmaktan çekinmeyin.