
Bu makalemizde sizlere elimden geldiğince veri bilimine gönlünü kaptırmış insanların sıkça kullandığı "Lineer Regresyon" yöntemini python üzerinde kendinizin nasıl kullanacağını anlatacağım. İlk olarak Lineer Regresyon'un ne olduğundan bahsedelim.
Lineer Regresyon: Lineer regresyon yöntemi iki skaler değişken arasındaki istatistiki (tahmini) ilişkiyi incelememizi sağlayan bir analiz yöntemidir. İstatistiki olmayan ilişkiye Celcius ve Fahrenheit sıcaklık birimleri verilebilir. Aralarında belirli bir fonksiyon vardır.

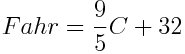 İstatistiki ilişkilerde ise elimizdeki bir kısım verilere bakarak aralarında farazi bir ilişki çıkarılır. Lineer regresyon hakkında daha detaylı bilgi edinmek isterseniz İlker Birbil hocanın anlattığı Tahmin ve Çıkarım serisini izleyebilirsiniz. Eğer hepsini izlemeye vaktiniz yoksa, bu yazıda yaptığımız şeyleri anlatan bölüme de şuradan ulaşabilirsiniz.
İstatistiki ilişkilerde ise elimizdeki bir kısım verilere bakarak aralarında farazi bir ilişki çıkarılır. Lineer regresyon hakkında daha detaylı bilgi edinmek isterseniz İlker Birbil hocanın anlattığı Tahmin ve Çıkarım serisini izleyebilirsiniz. Eğer hepsini izlemeye vaktiniz yoksa, bu yazıda yaptığımız şeyleri anlatan bölüme de şuradan ulaşabilirsiniz.
İki videoyu da izleyemeyenler için ise kısa bir özet geçmek gerekirse eğer:
Lineer regresyonda tahminleme yapabilmemiz için bir model kurmamız gerekmekte. Kuracağımız model aşağıdaki gibi olacak.
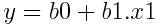

-
"b0" değeri bizim sabit değerimiz.
-
"b1" değeri ise modelimizin eğimini temsil ediyor.
-
"x1" değeri ise tahminleme yapılacak noktayı temsil ediyor.
Pythonda yapacağımız kısım ise buradaki "b0" ve "b1" değerlerini bulmak olacak. Buradaki değerleri bulmanın bir çok yolu olsada ben bu yazıda "En Küçük Kareler Yöntemi" ni kullanacağım. Bu yönteme göre
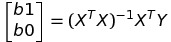
 Denklemini kullanarak "b1" ve "b0" değerlerini bulabiliyoruz. Bu fonksiyonun nereden çıktığı hakkında Türkçe okuma yapmak isterseniz, şuradan ulaşabilirsiniz. Buradaki ^T işareti o matrisin Transpozunun alınmasını, ^-1 işareti de o matrisin tersinin alınması gerektiğini söylüyor. Bu işlemlerin ne olduğunu bilmiyorsanız eğer transpoz hakkında şuradan, tersini alma işlemi içinde şuradan okuma yapabilirsiniz.
Denklemini kullanarak "b1" ve "b0" değerlerini bulabiliyoruz. Bu fonksiyonun nereden çıktığı hakkında Türkçe okuma yapmak isterseniz, şuradan ulaşabilirsiniz. Buradaki ^T işareti o matrisin Transpozunun alınmasını, ^-1 işareti de o matrisin tersinin alınması gerektiğini söylüyor. Bu işlemlerin ne olduğunu bilmiyorsanız eğer transpoz hakkında şuradan, tersini alma işlemi içinde şuradan okuma yapabilirsiniz.
Artık işin teori kısmını hallettiysek kod yazma kısmına başlayabiliriz demektir.
Kullanacağımız Kütüphaneler
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('seaborn')
- Yapacağımız tüm işlemlerimizi matrisler üzerinde yapacağımızdan "Numpy" kütüphanesini kullanacağız.
-
Gelen veriler büyük ihtimalle pandas kütüphanesinin veri tutma objesi olan Data Frame halinde geleceğinden o durum için de gerekli kodlamaları yapabilmek için pandas kütüphanesini import ediyoruz.
-
Pyplot kütüphanesini bitişte kullanacağımız görselleştirme işlemleri için tanıtıyoruz. Ben ekstradan bir de "Seaborn" tema stilini kullansın diye bir ekleme yaptım ama yapmanız zorunlu değildir.
Kütüphane tanımlamalarını da yaptığımıza göre oluşturacağımız modülümüzü class olarak tanıtarak başlıyoruz. Ardındanda objemiz ilk oluşturulacağı anda tanımlanmasını istediğimiz değişkenlermizi ekliyoruz.
class LineerRegresyon:
def __init__(self, w_intercept=True):
self.coef_ = None
self.intercept = w_intercept
self.is_fit = False
Buradaki tanıttığımız değerlere bakarsak eğer:
-
Coef: yukarıda tanıtmış olduğumuz b0 ve b1 değişkenlerini tutacağımız değişken.
-
Intercept, kullanıcı objesini oluştururken sabit değer katmak istemiş mi, istememiş mi onu tuttuğumuz kısım.
-
Is fit değişkeninde ise bu objede daha öne fit fonksiyonunu çalıştırıp çalıştırmadığımızı kontrol etmek için koyuyoruz.
Objemizin içine yazacağımız ilk metot "fit". Veri bilimine aşina olan insanların çok sıklıkla kullandığı bu fonksiyonda "b0" ve "b1" değerlerinin hesaplanılmasını halledeceğiz.
def fit(self, X, y):
# eğiteceğimiz verileri, işlemleri matrisler üzerinde yapacağımızdan dolayı array haline getiriyoruz.
X = self.convert_to_array(X)
y = self.convert_to_array(y)
Metodumuzun alabileceği parametrelerde ilk olarak objenin kendisine erişebilmemiz için "self", ardından da çıkarım yapacağımız ( yukarılardaki tahminleme değeri diye tanıttığımız) değerleri tutacağımız değişken ve son olarak da almış olduğumuz tahminleme değerlerine karşılık gelen sonuçları tutacağımız y parametresi. Yorum satırında da yazdığım gibi işlemleri yapabilmemiz için elimizdeki verileri işleyebilmemiz için array yani dizi haline getirmeliyiz ki işlemler yapabilelim. Burada "convert_to_array" adında bir fonksiyon görüyorsunuz. Bu fonksiyonu da biz yazacağız. Bu yüzden "fit" fonksiyonumuzu yazmaya ara verip "convert_to_array" adında yeni bir fonksiyon daha oluşturalım.
def convert_to_array(self, x):
x = self.pandas_to_numpy(x)
x = self.handle_1d_data(x)
return x
Bu fonksiyon içerisinde de yine bizim yazdığımız iki fonksiyon içerisine atıfta bulunulmakta. İlk yazacağımız fonksiyon adı üstüne pandas objesi olarak gelen verileri nump array ine çevirmek için. İkincisi ise tek boyutlu gelecek olan verileri iki boyutlu yapmamızı sağlayacak bir fonksiyon olucak.
def pandas_to_numpy(self, x):
if type(x) == type(pd.DataFrame()) or type(x) == type(pd.Series()):
# Pandas kütüphanesinin verdiğimiz data frame'i nump array'ine çevirdiği fonksiyon
return x.as_matrix()
if type(x) == type(np.array([1, 2])):
return x
return np.array(x)
Bu fonksiyonumuzda yine objenin kendisini ve çevireceği verileri tutan toplamda iki parametreyle çalışmakta. İçeride yazmış olduğumuz if metodunda ilk koşulumuz gelen verinin tipinin DataFrame olmasını, ikinci koşumuzda yine pandas kütüphanesinin bir obje tipi olan Series tipinde mi diye kontrol etmekte. Eğer iki koşuldan herhangi birinden "true" (doğru" dönerse ise pandas kütüphanesinin sağladığı bir özellik olan "as_matrix()" diyerek numpy kütüphanesinin arrayi olarak geri döndürüyoruz.
Eğer kodumuz burada çıkmazsa ve devam ederse karşısına bir koşul daha gelmekte. Burada ise gelen veririnin tipinin numpy array'i olup olmadığını kontrol ediyoruz. Eğer doğru dönerse, veriye hiç dokunmadan geri döndürüyoruz.
Her şeye rağmen yine devam ederse eğer numpy'ın kendi özelliği olan, verdiğiniz verileri array olarak almanızı sağlayan metod içerisinde verilerimizi geri gönderiyoruz. Bu sayede bir çok veri tipini karşılayabilecek bir metot yazmış olduk.
Sıra geldi convert_to_array fonksiyonunda yazan ikinci fonksiyona. "Handle_1d_data" adlı fonksiyonumun kodları şu şekilde olacak:
def handle_1d_data(self, x):
""" Eğer tek satırlık bir veri seti gelmişse elimize, hepsini tek bir sütüna çeviriyoruz.
Transpozunu alıyoruz yani."""
if x.ndim == 1:
x = x.reshape(-1, 1)
return x
Bir önceki satırda elimizdeki tüm verileri numpy haline getirdiğimizden dolayı artık nump kütüphanesinin nimetlerinden faydalanabiliriz. Bu fonksiyonumuzun içine ilk yazmış olduğumuz koşulda elimizdeki verinin kaç boyutlu olduğunu kontrol ediyoruz. Eğer tek boyutlu ise, reshape diyerek iki boyutlu hale getirebiliyoruz.
Bu sayede artık elimize gelebilecek verilerin değişken tipi problemlerinin büyük bir çoğunluğunu çözmüş olduk. Artık "fit" metodumuza devam edebiliriz. "convert to array" metodundan sonra işlemlere başlamadan önce kullanıcıdan aldığımız sabit kullanılsın mı, kullanılmasının cevabına göre elimizdeki veriye bir sabit eklemeliyiz. Bunu nasıl yapacağız derseniz eğer anlatayım. Bizim bulmak istediğimiz iki tane "b0" ve "b1" olmak üzere iki parametremiz vardı. Yukarıda görsel olarak da anlattım zaten. Burada "b0" terimini sabit olarak tanıtmıştık. Bazı durumlarda analize göre sabit kullanılmak istenmeyebilir. Bu yüzden sadece "b1" değeriyle tahminleme yapılacak değer çarpılarak bir sonuç elde edilir. Biz en başta kullanıcılarımızdan bunu tercih etmelerine imkan verecek parametreyi tanımlamıştık zaten. Bu değeri kontrol ederek bir if yazalım. Ardından da içine bir sabit eklememizi sağlayacak fonksiyonu çağıralım. Kod olarak:
if self.intercept:
X = self.add_intercept(X)
"add_intercept" fonksiyonunda ise ne yapacağımı kağıt üzerine anlatmak gerekirse:
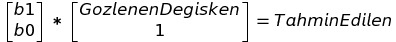

Burada göreceğiniz üzere iki matrisi çarpıyoruz ve sonuçta tahmin edeceğimiz değer çıkıyor. Yukarıdaki görselleştirme de sabit eklenen halini görüyorsunuz. Eğer sabit eklenmek istemeseydi hesap şöyle yapılacaktı:

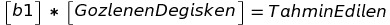
"b0" parametresini aradan çıkararak sadece "b1" parametresiyle işlem yapmış olduk. Şimdi bunu koda dökelim:
def add_intercept(self, X):
rows = X.shape[0] # Kaç satırlık bir veri olduğuna bakıyoruz.
inter = np.ones(rows).reshape(-1,1)
return np.hstack((X,inter))
Numpy kütüphanesi vermiş olduğunuz numara kadar "1" içeren array oluşturabiliyor. Bunun içinde biz elimizdeki verilerin satır uzunluğunu alıyoruz. Ardındanda bahsetmiş olduğum metoda kaç satır olduğunu verdikten sonra da elimizdeki veriyle işlem yapılabilmesi için tekrardan boyutunu değiştiriyoruz. Son olarakta yine numpy kütüphanesinin metodu olan hstack sayesinde iki array'i yatay toplama işlemi yaptırarak geri döndürüyoruz.
Şimdi en tepede bahsetmiş olduğumuz fonksiyonu koda dökme vakti. Bunun için sürekli yukarı in çık yapmamanız için resmi bir daha koyuyorum.
Aşama 1:
Aşama 2:
Aşama 3:
Bunları kod olarak "fit" metodunun altına yazalım.
def fit(self, X, y):
X = self.convert_to_array(X)
y = self.convert_to_array(y)
if self.intercept:
X = self.add_intercept(X)
# Aşama 1:
temp_xtx = np.linalg.inv(np.dot(X.T,X))
# Aşama 2:
temp_xty = np.dot(X.T,y)
# Aşama 3:
self.coef_ = np.dot(temp_xtx,temp_xty)
self.is_fit = True
Tüm aşamaları rahat rahat takip etmeniz için yukarıdaki anlatım yoluyla aynı yerlere yazdım. Burada kullanılan numpy'ın "dot" fonksiyonu matris çarpımını, "linalg.inv" tersini almayı sağlamakta. Dilerseniz ikisinin de açıklama sayfalarına şuradan ve şuradan gidebilirsiniz. Görmüş olacağınız üzere 3. aşamada çıkan 2x1 boyutlu, bizim "b0" ve "b1" değerlerini içeren matrisimizi objemizin coef_ değişkenine atadıktan sonra "is_fit" değişkenimizi true yapıyoruz, daha sonra kullanmak için. Artık modelimiz verilen değere göre tahmin yapabilmesi için gerekli parametrelere sahip.
Peki tahminlemeyi nasıl yapacağız? Bunun için ise "predict" yani tahmin etme fonksiyonunu yazmalıyız. İlk olarak is_fit parametremizi kontrol ederek, tahmin edebilmemiz için gereken değerlere sahip olup olmadığımıza bakıyoruz. Eğer fit edilmişse, elimizdeki veriyi kullanabileceğimiz bir hale getirmek için daha önce yazdığım "convert_to_array" metodumuza sokuyoruz. Eğer objemiz yaratılırken sabit değer kullanımı istenmişse, bize verilen veriye de yine sabit değer işleminde kullanmak için "1" ekliyoruz. Bunu da yaptıktan sonra matrisimiz işlem yapılabilir hale geldiğinden "coef_" parametremizde bulunan "b0" ve "b1" değişkenleriyle verileri çarparak tahmimizi geri döndürüyoruz. Kod olarak nasıl yapıldığına bakacak olursak:
def predict(self, X):
if not self.is_fit:
raise ValueError("Fit etmeden bir yere gitmez bu fonksiyon")
X = self.convert_to_array(X)
if self.intercept:
X = self.add_intercept(X)
return np.dot(X,self.coef_)
Bu kadar şeyi yaptık fakat başarımızı nasıl ölçeceğiz? Bunun için "Ortalama hata kareleri toplamı kökü" dediğimiz bir kontrol mekanizmamız bulunmakta. Bu kontrol mekanizması bizim tahminlediğimiz değerler ile gerçek değerleri arasındaki farkları ölçerek bize bir değer döndürüyor. Bütün değerleri yakalamanız durumunda "0" dönmesi gerekir. Bu yüzden de ne kadar "0" a yakın bir değer dönmüşse modeliniz o kadar doğrudur diyebiliriz. Ortalama hata kareleri toplamı kökü testi hakkında okuma yapmak isterseniz eğer şuradan yapabilirsiniz. Biz koda ise şöyle döküyoruz:
def score(self, X, y):
X = self.convert_to_array(X)
y = self.convert_to_array(y)
pred = self.predict(X)
return np.mean((np.array(pred)-np.array(y))**2)
Burada fark edeceğiniz üzere ekstradan sonuçlarımızı da verdik diğer metodlara göre çünkü dediğim gibi tahminleme yaptığımız değerlerin uzaklığını bulabilmemiz için gerçek değerleri de bilmemiz gerekmekte. Klasik olarak verileri kullanabileceğimiz hale getirdikten sonra gözlenen değişkenlerle tahminlememizi yapıp, tahminlenen değişkenden gerçek değeri çıkarıp karesini aldıktan sonra toplam değeri geri döndürüyoruz. Bu sayede elimize skorumuz geçmekte.
Peki o kadar kod yazdık, bunlar çalışacak mı dediğinizi duyar gibiyim. Bunun için ben kaggle (veri bilimcilerin aktif kullandığı bir platform) üzerinde ders notlarının paylaşıldığı bir veri seti buldum. Buradaki matematik notlarının diğer notlarıyla bir ilişkisi olup olmadığına bakalım isterseniz. Veriye şuradan erişebilirsiniz. Ben ismini de değiştirip kodumun çalıştığı dizin içerisine taşıdım. Bir data frame üzerine almak için pandas kütüphanesini kullandım:
df = pd.read_csv("train.csv")
df.head()
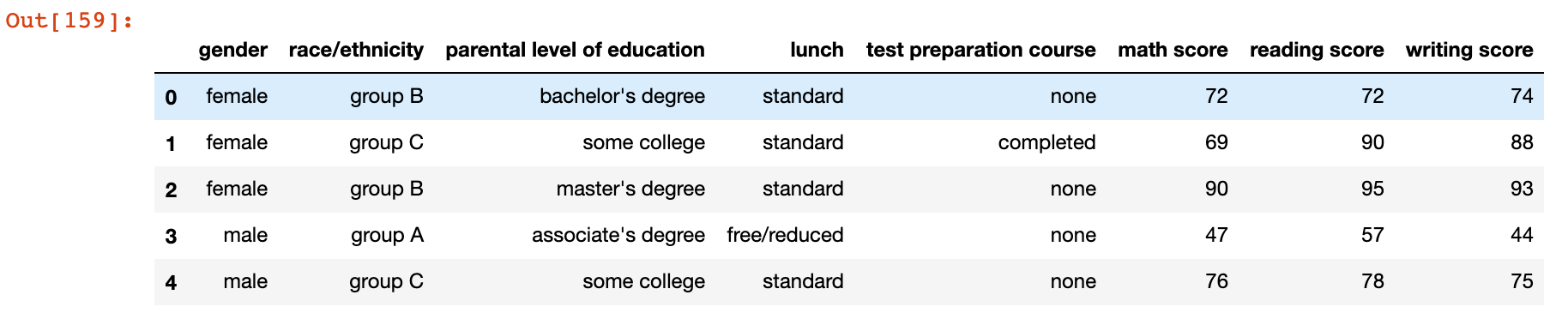
Göreceğiniz üzere elimizde öğrencinin bir takım verileri bulunmakta. Bizim burada bakmak istediğimiz daha önceden de dediğim gibi matematik notuyla diğer derslerinin notu arasında bir ilişki var mı? Bunu kıyaslamak için ben matematik skoruyla "yazma" yani büyük ihtimal kompozisyonu kast eden puanına bakacağım. Verimizden bu iki sütunu alıp başka bir data frame üzerinde birleştirelim.
s1 = pd.Series(df["math score"])
s2 = pd.Series(df["writing score"])
new_frame = pd.concat(objs=(s1 , s2), axis=1)
new_frame = new_frame.astype(int)
Ardından eğer daha önce yaptıysanız bileceğiniz üzere verimizi eğitirken bir kısmını eğitmek, bir kısmını da test için ayırmamız gerekmekte. Kendi modülümüzü yazdığımızdan dolayı bu işi de bizim yapmamız gerekecek. İsterseniz siz kendi fonksiyonunuzu yazabilirsiniz ama ben direkt data frame özelliği olan köşeli parantezlerle veriyi sınırlandırarak böldüm. Dediğim gibi sizde farklı yollarla bölebilirsiniz.
train_df = new_frame[0:int((len(new_frame)*70)/100)]
test_df = new_frame[int((len(new_frame)*70)/100):len(new_frame)]
Burada ben veriyi bölerken %70 lik bir kısmını eğitime, %30 luk bir kısmınıda test için ayırdım. Sıra geldi verimizle modelimizi eğitmeye.
X = train_df["math score"]
y = train_df["writing score"]
lr = LineerRegresyon(w_intercept=True)
lr.fit(X,y)
lr.coef_
Ben sabit kullanarak eğitmek istediğimden, objemi oluştururken "w_intercep" parametremi "true" olarak tanımladım.
Ardındanda objemin içindeki "fit" fonksiyonuna gerekli verileri verdikten sonra da aldığı ağırlıkları görmek istediğimden, objemizdeki ağırlıkları tuttuğumuz "coef_" değişkenini çağırdım.


Matristen görebileceğiniz üzere "b1" değişkenimiz 0,8 değerini, "b0" değişkenimiz ise "14" değerini almış. İsterseniz test etmek için bir deneme yapalım. Diyelim ki matematikten 70 alan bir öğrenci kompozisyonda kaç alır?


Göreceğiniz üzere 71 alacağını düşünüyor. Güzel en azından bir çıktımız var artık. Sırada artık bunu görselleştirmek var. Bunun için ilk olarak elimizdeki test verisine bir bakalım, gerçekte aralarında nasıl bir ilişki bulunmakta:

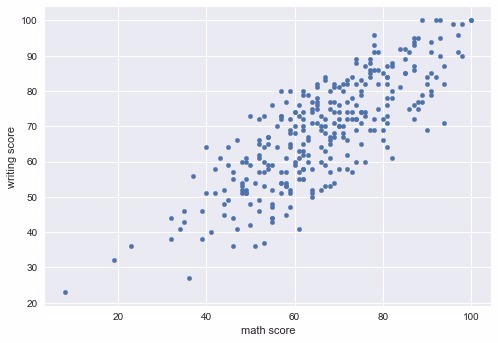
İnsan gözüyle bile bakarak aralar��nda bir ilişki bulunduğunu söyleyebiliriz fakat bakalım, kendi yazdığımız model bunu yakalayabilmiş mi? Bunu görmek için yine arkada gerçek verileri tutarak bizim tahmin ettiğimiz verileri üzerine çizgi olarak basabilecek bir kod yazmamız gerekiyor. Kendiniz de deneyebilirsiniz fakat ben hemen nasıl olacağını şöyle gösteriyim:
X = pd.Series(test_df["math score"])
y = lr.predict(test_df["math score"]).tolist()
test_df.plot.scatter(x="math score", y="writing score")
plt.plot(X,y,color="green")
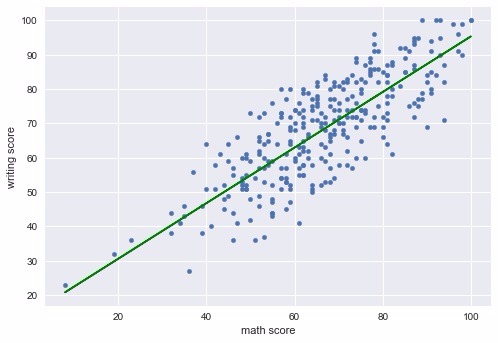 Evet görünen o ki, modelimizde böyle bir ilişki olduğunu fark edebilmiş. Son olarak da göze güzel gelsede, aslında ne kadarlık bir sapmayla tahmin edebilmişiz bunu görmek için skor fonksiyonumuzu çalıştıralım.
Evet görünen o ki, modelimizde böyle bir ilişki olduğunu fark edebilmiş. Son olarak da göze güzel gelsede, aslında ne kadarlık bir sapmayla tahmin edebilmişiz bunu görmek için skor fonksiyonumuzu çalıştıralım.
lr.score(train_df["math score"],train_df["writing score"])
"82.38" puanlık bir sapma yapmışız. 0'a çok yakın olmasak da bu kadar dağınık bir veri kümesi için iyi bir sonuç.
Yazımı okuyan herkese çok teşekkür ederim. Ayrıca yazıda bir hata saptadıysanız da benimle irtibata geçebilir veya yorum olarak atabilirsiniz. Umarım faydalı olmuştur. İyi çalışmalar.
Kodların hepsini bir arada görmek isterseniz eğer veriyle birlikte notebook halini şuradaki github reposunda bulabilirsiniz.