Python Kullanarak Ekşi Sözlük Başlıklarını Toplamak
Siteleri test etmek için yazılmış olan Selenium kütüphanesini kullanarak ekşisözlük'de geçmişte ve bugün gündem olan başlıkları çekiyoruz.


Bu makalemizde sizlere “ekşisözlük” ten nasıl gündem başlıklarını çekebilirsiniz onu anlatacağım. Yapmayı öğrendiğiniz şeyi istediğiniz şekilde daha sonradan kullanabilirsiniz. Şimdilik “Ne yapıcaz ki başlıkları çektikten sonra?” sorusuna cevap olarak ben size çektiğimiz başlıkları, ağırlıklarına göre bir kelime bulutu üzerinde çıktı almayı göstereceğim. İlk olarak kullanacağımız kütüphaneleri kodumuzda tanıtalım:
# Kullanacağımız kütüphaneleri tanıtarak başlıyoruz.
# Bot için kullandığım kütüphaneler
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.keys import Keys
# Dinamik olmasını istemem sebebiyle güncel tarihi alabilmem için gereken kütüphane
import datetime
# Metin analizi için gereken kütüphaneler
from string import punctuation, digits
from wordcloud import WordCloud # Görselleştirme
import matplotlib.pyplot as plt # Görselleştirme
# Çıktı alma işlemi için kullandığım kütüphaneler
import numpy as np
from PIL import ImageKod içerisinde de bahsettiğim üzere yazılımı her çalıştırışımızda kendiliğinden ben bir şeye müdahale etmek zorunda olmadan çalışabilsin diye tarih verisini de kodu çalıştırdığınız sistemin (bilgisayarınız) anlık tarih ve saat bilgilerini alıyoruz. Fakat kullandığım kütüphanede ay verisini eğer metin olarak bastırmaya çalışırsak ingilizce çıktı veriyor. Bunun için bende bir sözlük oluşturarak anlık gelen ayın numarasına göre türkçe karşılığını döndürmesini sağladım. Bunun için gerekli tanımlamaları yapmak gerekirse:
aylar= {
1:”Ocak”,
2:”Şubat”,
3:”Mart”,
4:”Nisan”,
5:”Mayıs”,
6:”Haziran”,
7:”Temmuz”,
8:”Ağustos”,
9:”Eylül”,
10:”Ekim”,
11:”Kasım”,
12:”Aralık”
}
bugun = datetime.datetime.now()Şimdi elimizde tarihimiz de bulunmakta, artık kodları yavaş yavaş çalıştırmamızın vakti geldi. İlk yazacağımız fonksiyon bizim vereceğimiz tarihe gidip, o tarihte gündem olan başlıkları çekecek. Bunun için ay ve gün vermek zorunda değiliz çünkü ekşisözlük geriye dönük sadece o güne ait verilere bakmanıza izin veriyor. Yani aynı anda 2002 yılına kadar aynı günün tüm başlıklarına bakabilirsiniz ama diğer günlere bakamıyorsunuz. Bunun için sadece yıl verisini yollamamız yeterli bizim için. Kullanacağımız yıl verisini de aldıktan sonra botumuzu çalıştıracağız. Bot için selenium adlı kütüphaneyi kullandım. Bu kütüphane sayesinde yazacağınız bot insan gibi davranabiliyor. Bu sayede bazı siteler tarafından direk sitenin yüklenmesiyle gelmeyip, siz bir şeylere tıkladıkça gelen şeyleri çekebiliyorsunuz. Ayrıca çekeceğimiz başlıkların internet sitesi üzerindeki adreslerini göstermek için XPATH halini kullanıyoruz. Bu Xpathi almak için şu yöntemi istediğiniz sitede kullanabilirsiniz:
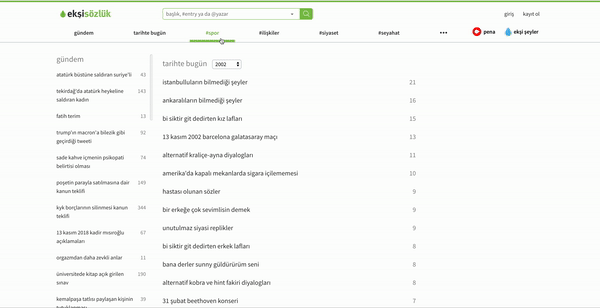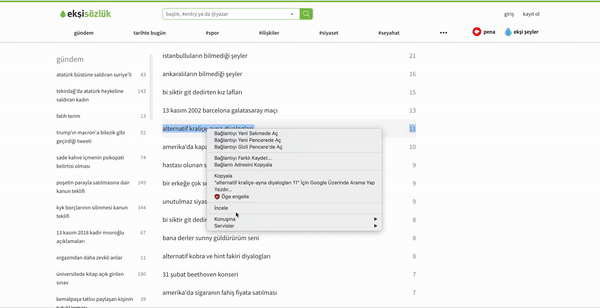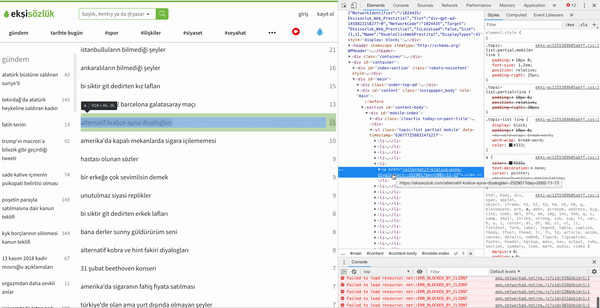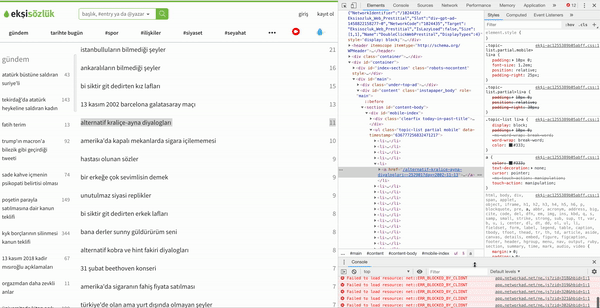
Adresimizide aldıktan sonra artık kodumuzu yazabiliriz.
def getThisYearHeaders(year):
‘’‘
Bu fonksiyon ile parametre olarak verilen yılda bugün gündem olan başlıkları çekiyoruz.
‘’‘
# Botun gideceği adresi tanıtıyoruz.
url = “https://eksisozluk.com/basliklar/m/tarihte-bugun?year=” + year
# Bot için bir sekme açıyoruz.
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get(url)
headers = “”
# Gidilen adresteki başlıkların genel olarak içinde bulunduğu adresi xpath olarak veriyoruz.
select_element = driver.find_elements_by_xpath(’//*[@id=”mobile-index”]/ul/li’)
# Ardından bu adreste bulunan her bir başlığı bir stringe alıyoruz.
for option in select_element:
headers= headers + “ “ + (option.find_element_by_xpath(’a’).text)
cevirici = str.maketrans(’‘, ‘’, punctuation) # Noktalama işaretlerini kaldırıyoruz.
headers = headers.translate(cevirici)
cevirici = str.maketrans(’‘, ‘’, digits) # Numaralardan arındırıyoruz
headers = headers.translate(cevirici)
headers = headers.split() # Ardından içindeki her bir kelimeyi tek tek bir kelime olarak listeye alıyoruz.
headers = purge_from_garbage(headers) # Gereksiz kelimelerden arındırıyoruz.
return headers
Elimden geldiğince yorum satırlarıyla açıklamaya çalıştım. Anlamadığınız bir kısım olursa yorumlarda sormaktan çekinmeyin.
Şimdide kıyaslamamız için gereken günümüzün gündem başlıklarını çekme kısmına gelelim. Bu fonksiyon yukarıdaki fonksiyondan çok farklı değil. Sadece başlıkları çekeceğimiz “xpath” in adresi farklı.
def getTodayHeaders():
‘’‘
Bu fonksiyon ile kodun çalıştırıldığı sırada gündem olan başlıkları çekiyoruz.
‘’‘
url = “https://eksisozluk.com”
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get(url)
headers = “”
select_element = driver.find_elements_by_xpath(’//*[@id=”partial-index”]/ul/li’)
for option in select_element:
try:
headers= headers + “ “ + (option.find_element_by_xpath(’a’).text)
except:
continue
cevirici = str.maketrans(’‘, ‘’, punctuation)
headers = headers.translate(cevirici)
cevirici = str.maketrans(’‘, ‘’, digits)
headers = headers.translate(cevirici)
headers = headers.split()
headers = purge_from_garbage(headers)
return headersİncelerken fark edeceğiniz üzere “purge_from_garbage” adındaki bir metodumuz bulunmakta. Bu metot sayesinde de Türkçe içerisinde fazlaca kullanılan ve verimizi kirleten kelimelerden arındırıyoruz. Bu kısımda geliştirme aşamasında yayınlamış olduğum “Twitter” gönderilerinde durumu fark edip çözüm önerisi sunan “Mert Yüksekgönül“ e teşekkür ederim.
def purge_from_garbage(values):
output = []
stop_words = [”ekşi”,”sözlük”,”mi”,”acaba”,”acep”,”adamakıllı”,”adeta”,”ait”,”altmýþ”,”altmış”,”altý”,”altı”,”ama”,”amma”,”anca”,”ancak”,”arada”,”artýk”,”aslında”,”aynen”,”ayrıca”,”az”,”açıkça”,”açıkçası”,”bana”,”bari”,”bazen”,”bazý”,”bazı”,”başkası”,”baţka”,”belki”,”ben”,”benden”,”beni”,”benim”,”beri”,”beriki”,”beþ”,”beş”,”beţ”,”bilcümle”,”bile”,”bin”,”binaen”,”binaenaleyh”,”bir”,”biraz”,”birazdan”,”birbiri”,”birden”,”birdenbire”,”biri”,”birice”,”birileri”,”birisi”,”birkaç”,”birkaçı”,”birkez”,”birlikte”,”birçok”,”birçoğu”,”birþey”,”birþeyi”,”birşey”,”birşeyi”,”birţey”,”bitevi”,”biteviye”,”bittabi”,”biz”,”bizatihi”,”bizce”,”bizcileyin”,”bizden”,”bize”,”bizi”,”bizim”,”bizimki”,”bizzat”,”boşuna”,”bu”,”buna”,”bunda”,”bundan”,”bunlar”,”bunları”,”bunların”,”bunu”,”bunun”,”buracıkta”,”burada”,”buradan”,”burası”,”böyle”,”böylece”,”böylecene”,”böylelikle”,”böylemesine”,”böylesine”,”büsbütün”,”bütün”,”cuk”,”cümlesi”,”da”,”daha”,”dahi”,”dahil”,”dahilen”,”daima”,”dair”,”dayanarak”,”de”,”defa”,”dek”,”demin”,”demincek”,”deminden”,”denli”,”derakap”,”derhal”,”derken”,”deđil”,”değil”,”değin”,”diye”,”diđer”,”diğer”,”diğeri”,”doksan”,”dokuz”,”dolayı”,”dolayısıyla”,”doğru”,”dört”,”edecek”,”eden”,”ederek”,”edilecek”,”ediliyor”,”edilmesi”,”ediyor”,”elbet”,”elbette”,”elli”,”emme”,”en”,”enikonu”,”epey”,”epeyce”,”epeyi”,”esasen”,”esnasında”,”etmesi”,”etraflı”,”etraflıca”,”etti”,”ettiği”,”ettiğini”,”evleviyetle”,”evvel”,”evvela”,”evvelce”,”evvelden”,”evvelemirde”,”evveli”,”eđer”,”eğer”,”fakat”,”filanca”,”gah”,”gayet”,”gayetle”,”gayri”,”gayrı”,”gelgelelim”,”gene”,”gerek”,”gerçi”,”geçende”,”geçenlerde”,”gibi”,”gibilerden”,”gibisinden”,”gine”,”göre”,”gırla”,”hakeza”,”halbuki”,”halen”,”halihazırda”,”haliyle”,”handiyse”,”hangi”,”hangisi”,”hani”,”hariç”,”hasebiyle”,”hasılı”,”hatta”,”hele”,”hem”,”henüz”,”hep”,”hepsi”,”her”,”herhangi”,”herkes”,”herkesin”,”hiç”,”hiçbir”,”hiçbiri”,”hoş”,”hulasaten”,”iken”,”iki”,”ila”,”ile”,”ilen”,”ilgili”,”ilk”,”illa”,”illaki”,”imdi”,”indinde”,”inen”,”insermi”,”ise”,”ister”,”itibaren”,”itibariyle”,”itibarıyla”,”iyi”,”iyice”,”iyicene”,”için”,”iş”,”işte”,”iţte”,”kadar”,”kaffesi”,”kah”,”kala”,”kanýmca”,”karşın”,”katrilyon”,”kaynak”,”kaçı”,”kelli”,”kendi”,”kendilerine”,”kendini”,”kendisi”,”kendisine”,”kendisini”,”kere”,”kez”,”keza”,”kezalik”,”keşke”,”keţke”,”ki”,”kim”,”kimden”,”kime”,”kimi”,”kimisi”,”kimse”,”kimsecik”,”kimsecikler”,”külliyen”,”kýrk”,”kýsaca”,”kırk”,”kısaca”,”lakin”,”leh”,”lütfen”,”maada”,”madem”,”mademki”,”mamafih”,”mebni”,”međer”,”meğer”,”meğerki”,”meğerse”,”milyar”,”milyon”,”mu”,”mü”,”mý”,”mı”,”nasýl”,”nasıl”,”nasılsa”,”nazaran”,”naşi”,”ne”,”neden”,”nedeniyle”,”nedenle”,”nedense”,”nerde”,”nerden”,”nerdeyse”,”nere”,”nerede”,”nereden”,”neredeyse”,”neresi”,”nereye”,”netekim”,”neye”,”neyi”,”neyse”,”nice”,”nihayet”,”nihayetinde”,”nitekim”,”niye”,”niçin”,”o”,”olan”,”olarak”,”oldu”,”olduklarını”,”oldukça”,”olduğu”,”olduğunu”,”olmadı”,”olmadığı”,”olmak”,”olması”,”olmayan”,”olmaz”,”olsa”,”olsun”,”olup”,”olur”,”olursa”,”oluyor”,”on”,”ona”,”onca”,”onculayın”,”onda”,”ondan”,”onlar”,”onlardan”,”onlari”,”onlarýn”,”onları”,”onların”,”onu”,”onun”,”oracık”,”oracıkta”,”orada”,”oradan”,”oranca”,”oranla”,”oraya”,”otuz”,”oysa”,”oysaki”,”pek”,”pekala”,”peki”,”pekçe”,”peyderpey”,”rağmen”,”sadece”,”sahi”,”sahiden”,”sana”,”sanki”,”sekiz”,”seksen”,”sen”,”senden”,”seni”,”senin”,”siz”,”sizden”,”sizi”,”sizin”,”sonra”,”sonradan”,”sonraları”,”sonunda”,”tabii”,”tam”,”tamam”,”tamamen”,”tamamıyla”,”tarafından”,”tek”,”trilyon”,”tüm”,”var”,”vardı”,”vasıtasıyla”,”ve”,”velev”,”velhasıl”,”velhasılıkelam”,”veya”,”veyahut”,”ya”,”yahut”,”yakinen”,”yakında”,”yakından”,”yakınlarda”,”yalnız”,”yalnızca”,”yani”,”yapacak”,”yapmak”,”yaptı”,”yaptıkları”,”yaptığı”,”yaptığını”,”yapılan”,”yapılması”,”yapıyor”,”yedi”,”yeniden”,”yenilerde”,”yerine”,”yetmiþ”,”yetmiş”,”yetmiţ”,”yine”,”yirmi”,”yok”,”yoksa”,”yoluyla”,”yüz”,”yüzünden”,”zarfında”,”zaten”,”zati”,”zira”,”çabuk”,”çabukça”,”çeşitli”,”çok”,”çokları”,”çoklarınca”,”çokluk”,”çoklukla”,”çokça”,”çoğu”,”çoğun”,”çoğunca”,”çoğunlukla”,”çünkü”,”öbür”,”öbürkü”,”öbürü”,”önce”,”önceden”,”önceleri”,”öncelikle”,”öteki”,”ötekisi”,”öyle”,”öylece”,”öylelikle”,”öylemesine”,”öz”,”üzere”,”üç”,”þey”,”þeyden”,”þeyi”,”þeyler”,”þu”,”þuna”,”þunda”,”þundan”,”þunu”,”şayet”,”şey”,”şeyden”,”şeyi”,”şeyler”,”şu”,”şuna”,”şuncacık”,”şunda”,”şundan”,”şunlar”,”şunları”,”şunu”,”şunun”,”şura”,”şuracık”,”şuracıkta”,”şurası”,”şöyle”,”ţayet”,”ţimdi”,”ţu”,”ţöyle”]
for value in values:
if value != (aylar[bugun.month]).lower() and value not in stop_words:
output.append(value)
return outputŞimdi sırada oluşturmuş olduğumuz bu metotları çağırmak var. Çalıştırdıktan sonra botunuzu izlerken şu moda girmeniz çok muhtemel:

headers = getThisYearHeaders(str(bugun.year-10)) # 10 yıl önceki başlıkları çekiyoruz.
todayHeaders = getTodayHeaders() # Anlık gündem başlıklarını çekiyoruz.Şimdi gelelim bu çektiğimiz kelimeleri görselliştirmeye. Ben burada veri defteri sitesindeki şu makaleden fazlaca yararlandım: Türkçe Metin İşlemede İlk Adımlar
Yukarıda verdiğim yazıda anlatılanlara ek, aldığım çıktıları ekşi logosuna benzer şekilde almak istedim. Bunun için ise bize gereken tek şey ekşisözlük logosu. Benim kullandığım logoyu kullanmak isterseniz eğer:
Resme sağ tıklayıp, indir diyerek bilgisayarınızda şu an bu kodları çalıştırdığınız dizine “eksilogo.png” olarak kaydetmeniz yeterli.
Gelelim bu görselle elimizdeki kelimeleri kullanmaya. Bunun için elimizdeki logoyla kelimeleri word cloud kütüphanesinin emin ellerine bırakıyoruz. Bundan önce size burada yaşadığım süreci anlatmak istiyorum. Kodu ilk yazarken iki tane pyplot grafiğini pyplot üzerinde birleştirmek ve öyle çıktı almak vardı. Ne yazıkki uzun aramalarımın ardından istediğim şekilde birleştiren bir kod bulamadım. Bunun üzerine wordcloud kütüphanesinin hali hazırda çıktı almak için bir metotu olduğunu öğrendim. Bu sayede iki tane wordcloud grafiğini çıktı alıp birleştirim dedim lakin bu seferde başlıklarının da dinamik olmasını istediğimden, çıkartılan wordcloudlar, pyplot halinde olmadıklarından sadece iki tane wordcloudu birleştirip öyle çıktı alıyordu. Bu yüzden de günün sonunda iki tane ayrı ayrı pyplot çıktısı alıp daha sonradan “image” kütüphanesi ile açıp, birleştirme yoluna gittim. O yüzden aşağıdaki iki kod bloğu bilgisisayarlarınızda iki farklı dosya, ardından da onları birleştirdiğinden, kodun sonunda 3 tane dosya olarak bırakıyor. Eğer isterseniz kullanımdan sonra silmesini sağlayan bir kod yazabilirsiniz ama ben gerek görmedğimden yazmadım.
wave_mask = np.array(Image.open( “eksilogo.png”)) # Kullanacağım maskeyi veriyorum.
wordcloud = WordCloud(width=3000,height=3000,background_color=”white”,mask=wave_mask).generate(’ ‘.join(headers))
plt.figure(figsize=(9,10), dpi=108)
plt.title(”ekşisözlük “+ str(bugun.day) + “ “ + aylar[bugun.month] +” “+ str(bugun.year-10) +” Günü Gündem Kelime Ağırlığı”, fontsize = 20)
plt.imshow(wordcloud, interpolation=’bilinear’)
plt.axis(”off”)
plt.savefig(”eksi”+str(bugun.year-10) +”Gundem.jpeg”, dpi = 108)
plt.show()
wordcloud = WordCloud(width=3000,height=3000,background_color=”white”,mask=wave_mask).generate(’ ‘.join(todayHeaders))
plt.figure(figsize=(9,10), dpi=108)
plt.title(”ekşisözlük “+ str(bugun.day) + “ “ + aylar[bugun.month] +” “+ str(bugun.year) +” Günü Gündem Kelime Ağırlığı”, fontsize = 20)
plt.imshow(wordcloud, interpolation=’bilinear’)
plt.axis(”off”)
plt.savefig(”eksiBugunGundem.jpeg”, dpi = 108)
plt.show()
Almış olduğumuz bu çıktılarımızı birleştirip, yan yana koymamızı sağlayan kod blokları:
images_list = [’eksi2008Gundem.jpeg’, ‘eksiBugunGundem.jpeg’]
imgs = [ Image.open(i) for i in images_list ]
min_img_shape = sorted( [(np.sum(i.size), i.size ) for i in imgs])[0][1]
img_merge = np.hstack( (np.asarray( i.resize(min_img_shape,Image.ANTIALIAS) ) for i in imgs ) )
img_merge = Image.fromarray( img_merge)
img_merge.save( ‘eksicikti’+ str(bugun.day)+ aylar[bugun.month] + str(bugun.year-10) +’.jpg’ )Bu kodlar sayesinde de oluşturmuş olduğumu iki farklı görseli birleştirdik. Çıktımızı da dinamik olması açısından da tarih bazlı verdik.
Umarım yardımcı olabilmişimdir.Sizden de yaptığınız örneklerin çıktılarını bekliyorum.